Data CI: Entity Framework Core Migrations from Azure Pipelines to GitHub
Disclaimer: I imported this post from WordPress to Jekyll on 9/2/23. Forgive the misformatting until I get a chance to clean it up.
FilterLists is a hobby project that I have been hacking on for about five years as a labor of love. It serves as a useful resource for the adblocking community, but I have also used it as a playground to learn new skills.
I recently improved the continuous integration of the open-sourced data for the application by adding automatic Entity Framework Core data migrations. When a contributor opens a pull request changing any of the JSON data, an Azure Pipeline clones the contributor’s fork, adds an EF migration, performs a test seed, and pushes the migration back to the contributor’s fork to update the pull request.
History of FilterLists Data
Version 1: HTML Table in WordPress
I launched the first and second designs of FilterLists back in 2015 and 2017 as a simple WordPress installation with a table builder plugin. At the time, it only indexed a maximum of about 300 lists, and I managed updates myself through the WordPress back-end.
Community members could submit new lists through a contact form on the site, and I would have to update the table through tedious copy/paste and manually crafted HTML. It was easy to get up and running and served its purpose for a while, but this solution did not scale with a growing dataset now approaching 2,000 lists.
Version 2: ASP.NET API with Entity Framework Core
In 2018, I relaunched the site on React and ASP.NET Core. As a part of this process, I wanted to version control the data so community members could submit updates via GitHub pull requests. The dataset was becoming too large for me to maintain alone. I wanted to focus my limited time on the application itself and welcome community contributions to help keep the data up-to-date.
I chose Entity Framework Core and MariaDB for the data layer. I used EF code first for schema changes, but the data itself was stored in JSON flat files and merged into the production database at API startup.
At the time, EF Core 2.1 was at least six months away from release, so EF Core did not yet have native data seeding functionality. I managed to patch together a gnarly extension method to update the database from the JSON files. As I recall, it took me several weeks and many StackOverflow questions (e.g. 1, 2) to get this solution working correctly. The final product worked, but undoubtedly had security concerns and was impossible to comprehend or change later. For the next couple of years, I avoided making any schema changes as I feared to have to change my seeding algorithm.
Migrating the Data with Entity Framework Core
Deleting and Re-Inserting the Same Data
When EF Core 2.1 launched, I now had a native option for seeding the database. I could rely on EF Core to construct and order the required inserts/updates/deletes to keep the database in sync with the JSON data files. My initial attempt at converting to EF Core seeding discovered a bug in EF Core, however. The migration engine was deleting and re-inserting unchanged entities, adding a tremendous amount of no-ops to each migration script.
Stack Overflow Exceptions
The bug was fixed in EF Core 2.2, but it took me until a few months ago to prioritize moving to EF Core seeding again. The dataset had grown so large that my integration testing on the Azure Pipelines hosted agents started throwing stack overflow exceptions. (Sidebar: It is impossibly hard to Google for help on stack overflow exceptions when the primary repository of such information overloads the name “StackOverflow”.)
The free agent that Microsoft provides was running out of memory with my custom and inefficient seeding algorithm. My integration test spins up a new instance of the containerized database and tests seeding the latest JSON data. Since I relied on this testing to ensure that community-contributed data changes were valid (syntactically correct, foreign key relationships were correct, etc.), this was the trigger I needed to revisit EF Core’s native seeding.
Configuring JSON Seed Data with EF Core
My entities extend a BaseEntity. So, to instruct EF Core to seed the JSON data, I added a call to a new extension
method on Configure() of the BaseEntity. This method deserializes the JSON files into .NET objects using the new <a
href="https://docs.microsoft.com/en-us/dotnet/standard/serialization/system-text-json-overview">System.Text.Json</a>
library and adds them to the DbContext model by passing them into a call to HasData().
public class BaseEntityTypeConfiguration<TEntity> : IEntityTypeConfiguration<TEntity> where TEntity : BaseEntity
{
public virtual void Configure(EntityTypeBuilder<TEntity> builder)
{
...
builder.HasDataJsonFile<TEntity>();
}
}
BaseEntityTypeConfiguration.cs
using System.Text.Json;
public static class SeedExtension
{
public static void HasDataJsonFile<TEntity>(this EntityTypeBuilder entityTypeBuilder)
{
Guard.Against.Null(entityTypeBuilder, nameof(entityTypeBuilder));
var path = Path.Combine("../../../data", $"{typeof(TEntity).Name}.json");
if (!File.Exists(path)) return;
var entitiesJson = File.ReadAllText(path);
var entities = JsonSerializer.Deserialize<IEnumerable<TEntity>>(entitiesJson, new JsonSerializerOptions
{
PropertyNamingPolicy = JsonNamingPolicy.CamelCase
});
entityTypeBuilder.HasData((IEnumerable<object>)entities);
}
}
Now, when I add a new EF Core migration, the script captures not only schema changes but JSON data changes as well.
The odd cast to IEnumerable<object> in the call to HasData() is to ensure that the correct overload of HasData()
is being called. Ivan, “a legend amongst men,” explains it in further detail
here.
### Data Migration Limitations
It is important to note that EF Core’s seed functionality does not connect to a live database when adding a migration. This results in some key limitations that must be considered.
For FilterLists, I discovered quickly that foreign key constraints are not considered when adding a migration. In this pull request, a contributor removed some records from a primary entities collection but did not remove the corresponding records in a related many-to-many collection. Adding a migration seemed to work just fine, but applying the added migration to an instance of a real database flagged the issue before it made its way to production.
## Automatic Migrations with Azure Pipelines
This article is growing quite long. If you have glazed over thus far, this is the interesting part of this adventure, in my opinion.
The handful of community members who help me maintain the FilterLists dataset should not need to know anything about .NET, EF Core, etc. Unfortunately, they do have to know a bit about how databases work to understand the foreign key relationships in the JSON files, but I wanted to keep it as easy as possible for folks to contribute.
The goal of this endeavor was to build a CI Pipeline to automatically add data migrations and push them back to the pull request on the contributor’s behalf. I will explain how this works in a bit more detail, but here is the resulting Pipeline definition.
### Pushing to a Contributor’s Pull Request
On GitHub, when a pull request is created, the branch used for the PR is part of the forked repository (owned by another user). For my Migrate Pipeline to push the new migration back to the pull request, I had to check out the branch from the contributor’s fork, commit the new migration to that branch, and then push the change back to their repository (via GitHub Docs). The contributor must grant me permission when opening their PR for me to do so.
I could not find any simple/native task for pushing to somebody else’s git repository in Azure Pipelines. It is certainly possible that I missed something, however; and I did all of this custom work for nothing but my education.
The most difficult part of getting this working using custom bash tasks was getting the URI of the forked git
repository used to create the pull request. Azure Pipelines provides
many predefined
variables, but
unfortunately, the PR source repository URI is not a variable they offer
(yet).
I ended up curl-ing the GitHub API and piping the result into <a href="https://stedolan.github.io/jq/">jq</a> to
capture the fork URI.
- task: Bash@3
displayName: checkout source branch
inputs:
targetType: inline
script: |
FORKURI=$(curl -X GET "https://api.github.com/repos/$BUILD_REPOSITORY_NAME/pulls/$SYSTEM_PULLREQUEST_PULLREQUESTNUMBER" | jq -r '.head.repo.clone_url')
git clone --single-branch -b "$SYSTEM_PULLREQUEST_SOURCEBRANCH" "$FORKURI" .
azure-pipelines.migrate.yaml#L21
Installation and Configuration
If you are following along, the next few steps in the Pipeline are some preparation for adding the migration.
abort if just
migrated
bails out of the Pipeline if the last commit to the branch was from itself. I could not figure out a way to avoid
triggering the Migrate Pipeline again after pushing the new migration to the PR, so I just bail early here instead to
avoid an infinite loop. To abort but still report a successful Pipeline run, it outputs an aborted variable that all
future steps check in their condition.
use latest dotnet
sdk
and install ef dotnet
tool
ensure that the correct tools are installed in the hosted agent to add the EF core migration.
git
config
configures the username and email address of the Pipeline’s git committer.
Revert Existing PR Migration
Since I only want each PR to include a single new EF migration, the next step is to check if a migration has already been added for the current PR and revert it. I used the EF CLI to query the existing migrations list and check for the existence of the current PR number.
- task: Bash@3
displayName: revert existing PR migration
condition: and(eq(variables['abortJustMigrated.aborted'], 'false'), succeeded())
env:
GITHUBNAME: $(GITHUBNAME)
inputs:
targetType: inline
workingDirectory: server/src
script: |
MIGLIST=$(dotnet ef migrations list -p FilterLists.Data.Migrations -s FilterLists.Api)
echo "$MIGLIST"
if [[ $MIGLIST == *$SYSTEM_PULLREQUEST_PULLREQUESTNUMBER ]] ; then
echo "A migration already exists for PR #$SYSTEM_PULLREQUEST_PULLREQUESTNUMBER. Reverting..."
REVERTHASH=$(git log -n 1 --author="$GITHUBNAME" --grep="migrate PR #$SYSTEM_PULLREQUEST_PULLREQUESTNUMBER" --pretty=format:"%H")
git revert --no-edit "$REVERTHASH"
fi
azure-pipelines.migrate.yaml#L70
Sync with Upstream
Before adding a new migration, I then wanted to ensure that the contributor’s fork branch had all of the latest data changes from the FilterLists master branch. To do that, I added the primary FilterLists repository as a remote and merged its master down to the local PR branch. If there are any merge conflicts, I just fail the Pipeline so that the contributor or myself can address those manually.
- task: Bash@3
displayName: sync with upstream
condition: and(eq(variables['abortJustMigrated.aborted'], 'false'), succeeded())
inputs:
targetType: inline
script: |
git remote add upstream https://github.com/collinbarrett/FilterLists.git
git fetch upstream
git merge upstream/master
CONFLICTS=$(git ls-files -u | wc -l)
if [ "$CONFLICTS" -gt 0 ] ; then
echo "Conflicts with upstream repository. Aborting..."
exit 1
fi
azure-pipelines.migrate.yaml#L87
Add and Commit Migration
Adding a new migration is a simple one-liner to the EF CLI. I decided on using the GitHub PR number as the name of the automatic migration by convention.
dotnet ef migrations add $(System.PullRequest.PullRequestNumber) -p FilterLists.Data.Migrations -s FilterLists.Api
azure-pipelines.migrate.yaml#L107
Before committing the new migration, I wanted to test to ensure that the migration applies a change of some kind. If the migration does apply a change, I then proceed with committing to the branch.
- task: Bash@3
displayName: commit or abandon no-op migration
name: commitOrAbandon
condition: and(eq(variables['abortJustMigrated.aborted'], 'false'), succeeded())
inputs:
targetType: inline
workingDirectory: server/src/FilterLists.Data.Migrations
script: |
DIFF=$(git status -s -- . | wc -l)
echo "$DIFF file(s) changed"
if (( $DIFF != 3 )) ; then
echo "No-op migration. Effective EF migrations add/change 3 files (.Designer.cs, .cs, and *ModelSnapshot.cs). Abandoning..."
else
git add .
git commit -m "migrate PR #$SYSTEM_PULLREQUEST_PULLREQUESTNUMBER"
echo "##vso[task.setvariable variable=committed;isOutput=true]true"
fi
azure-pipelines.migrate.yaml#L109
Test Migration
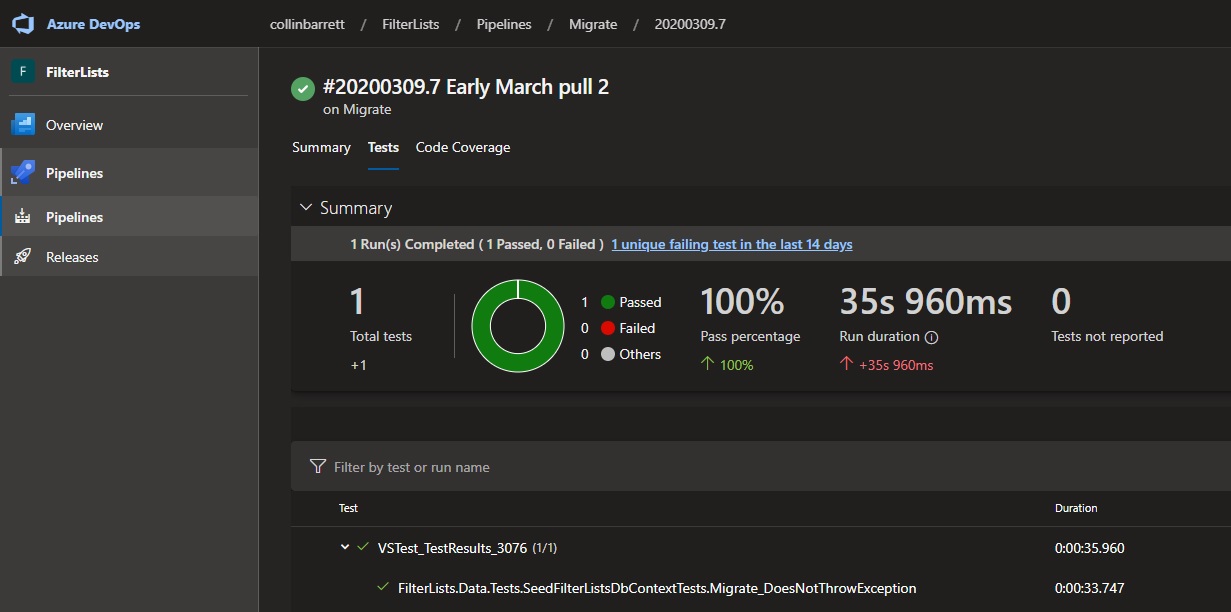
Before I push the new migration, I run the aforementioned integration test which uses Docker Compose to create a new instance of the API and the database. The test passes if data is seeded to the database without exception.
Push Migration
The last step is to push the changes back to the contributor’s PR branch. I am certain there is a better and more secure way of doing this, but for now, I am using the credential helper to push by injecting my GitHub PAT into the URL itself.
- task: Bash@3
displayName: push
condition: and(eq(variables['abortJustMigrated.aborted'], 'false'), succeeded())
env:
GITHUBPAT: $(GITHUBPAT)
inputs:
targetType: inline
script: |
git config --global credential.helper store
echo "https://$GITHUBPAT:[email protected]" >> ~/.git-credentials
git push origin "$SYSTEM_PULLREQUEST_SOURCEBRANCH"
azure-pipelines.migrate.yaml#L176
Applying Migrations on Startup
Now that I have migrations automatically added to pull requests which change data, I just need to ensure that the new
migrations are applied on every deploy to production. To do that, I make a call to the Migrate<TContext>() extension
method below before Run()-ing the IWebHost on API startup.
public static void Main(string[] args)
{
CreateWebHostBuilder(args)
.Build()
.Migrate<FilterListsDbContext>()
.Run();
}
public static class IWebHostExtensions
{
public static IWebHost Migrate<TContext>(this IWebHost webHost) where TContext : DbContext
{
using (var scope = webHost.Services.CreateScope())
{
var services = scope.ServiceProvider;
var context = services.GetService<TContext>();
context.Database.Migrate();
}
return webHost;
}
}
-IWebHostExtensions.cs
Next Steps
While I am quite happy with this new solution, there are still some further improvements that I would like to make.
- Evaluate if using an Azure Pipelines Repository Resource with a GitHub service connection to push to the forked repository is possible and better than using a personal access token. I have the PAT stored in a secret, but technically it grants access to all of my public repositories. I have a hunch that using a Resource is a more secure method.
- I have some API endpoints designed to serve a sorted version of the data as JSON to make it easier to apply sorting and linting conventions. To my knowledge, I am the only one who uses these currently, and I only clean up the JSON on occasion when I take the time to do so manually. As a part of this Migrate Pipeline, I would like to automatically sort and lint the JSON files and push them back to the pull request alongside the new migration.
- My top data contributor has for some time requested a UI for data change submissions. This would certainly be far more user-friendly than manipulating a database in JSON; I just have not carved out the time to build it yet. Maybe there is an off-the-shelf tool that could support this without building something custom?
- I have read some rumors lately that Microsoft’s long-term plan is to consolidate around the GitHub platform. Therefore, it might make sense to evaluate migrating my Azure Pipelines to GitHub Actions at some point.
Further Exploration
Just before publishing, I watched this new talk by Jimmy Bogard on CI/CD for databases. RoundhousE looks like a great tool to decouple migrations from EF, should that be needed. I probably will not try it with FilterLists in the near future, but I look forward to trying it in a future project.